How Cyberk Build an Indexer with Million QPS in 30 Days

In traditional system design, scalability often means building one massive architecture that handles millions of requests through centralized coordination and shared infrastructure. This model can work, but as systems grow, synchronization overhead, and maintenance complexity start to limit both performance and agility.
Cyberk has developed a more modern approach that takes the opposite direction. Instead of one large system serving everyone, each user or project operates within its own isolated environment — a dedicated database and API, automatically provisioned and deployed on AWS.
These micro-systems scale independently, matching their compute and storage precisely to the user’s real workload. By distributing workloads into thousands of lightweight, autonomous systems, the indexer achieves horizontal scalability by design. Each unit runs optimally within its boundary, while the overall infrastructure collectively supports millions of QPS through parallel execution.
In this article, let’s explore how such an architecture is built — from core design principles and data pipeline strategies to technical challenges and best practices that make million-QPS indexing possible.
Blockchain networks are scaling faster than ever. With the existence of high-scalability Layer 1s and Layer 2s like Sui, Polkadot or Fogo, the amount of on-chain data being generated has exploded. For businesses building on this data — whether in DeFi, GameFi, E-commerce, or enterprise blockchain applications , the real-time access to accurate, enriched information is no longer a luxury, but a necessity.
In traditional system design, scalability often follows a vertical model — building a single, centralized system powerful enough to handle millions of requests per second. This model works well in early stages, when the data volume and number of users are limited. However, as blockchain networks expand and data grows exponentially, the monolithic architecture begins to show its cracks.
When more users or new chains are added, the system grows heavier — databases expand, compute clusters need constant scaling, and caching layers become increasingly complex. Eventually, resource contention appears: a heavy query from one project can slow down others, and maintenance or upgrades turn into risky operations that affect the entire platform. The system may still function, but every improvement requires more coordination, more cost, and more effort to keep performance stable.
Distributed architecture takes a completely different path. Instead of concentrating all workloads in one large system, the indexer is broken down into many small, autonomous environments, each operating independently.
Every user or project has its own database and API instance, provisioned dynamically and deployed on AWS infrastructure. Rather than pushing one system to its physical limits, distributed indexing allows the platform to scale horizontally — by adding more lightweight systems instead of making a single one bigger.
Each unit can grow, shrink, or restart without disrupting others, resulting in predictable performance and simpler operations. Platforms like Covalent, Flipside Crypto, and Dune Analytics have adopted modular designs where multiple indexers run in parallel, each serving different chains or users.
In essence, the shift from traditional to distributed architecture redefines what scalability means — a network of smaller, smarter systems that work together seamlessly to achieve large-scale performance.
In blockchain, every transaction, token mint, or smart contract event generates data. To turn that ever-growing data stream into real-time, queryable insights, an indexer must balance three key goals:
To achieve that, Cyberk designed its large-scale indexer around a modular three-level architecture, optimized for distributed performance and horizontal scaling.
Data Ingestion Layer — This layer is responsible for connecting to the Aptos blockchain, continuously extracting transaction and event data, and storing them in their raw form.
Projects like The Graph also rely on node data, but their indexing depends on manual subgraph configurations.
Data Processing Layer — This layer takes the raw data, decodes and enriches it by combining it with external data sources, applies business logic, and structures it to make it query-ready. This is where token metadata, wallet analytics, or price feeds are merged with transaction data to give full context to every event.
Comparable to Flipside Crypto or Covalent, this layer serves as the “brain” of the system
Data Delivery Layer — This layer provides user-facing interfaces (APIs and UI). It allows users to query the processed data through public APIs and also offers tools for creating their own custom data pipelines (Custom Indexer Platform).
While Moralis and Dune Analytics offer query-based access, Cyberk goes further with automated schema generation powered by AI — allowing developers to onboard new contracts and start querying within minutes, not weeks.
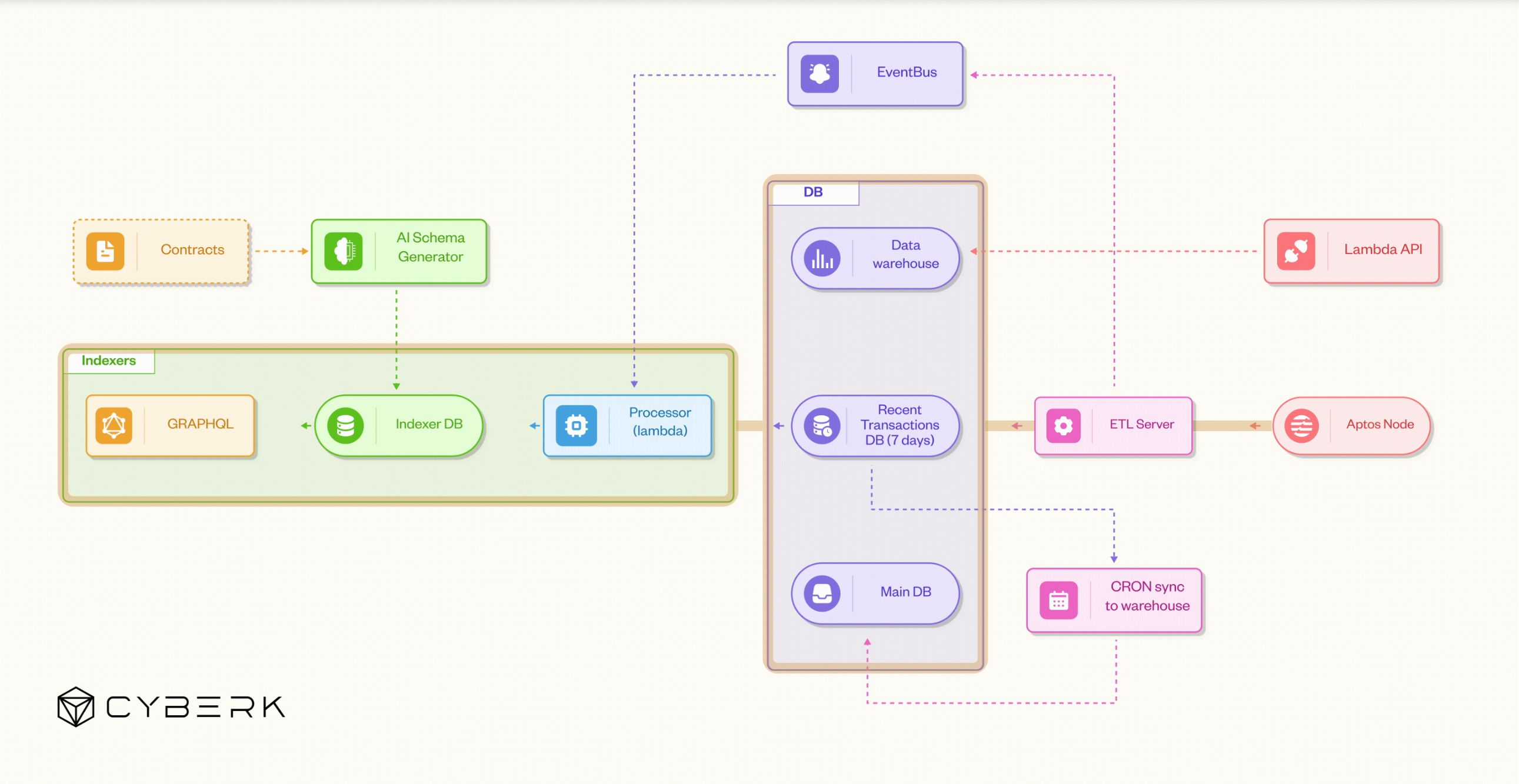
The workflow begins at the Aptos Node, the ultimate source of truth for all on-chain events.
This node continuously emits blocks, transactions, and contract events that represent the live state of the network.
The indexing system connects directly to the node through gRPC or JSON-RPC, streaming both historical and real-time data. This direct connection guarantees data integrity and enables full reproducibility — crucial when backfilling data or verifying chain states.
The ETL Server acts as the gateway between the blockchain and the rest of the indexing infrastructure. It extracts transaction streams from the node, performs lightweight transformations (batching, deduplication, checkpointing), and loads the data into downstream components such as the EventBus, Recent Transactions DB, or Data Warehouse.
It ensures the system can process millions of on-chain events continuously without data loss. Written in Rust or Go and deployed on Kubernetes, the ETL layer offers high throughput, fault tolerance, and automatic recovery.
Purpose: Reliable, real-time ingestion and historical synchronization of on-chain data.
The ETL Server routes data into two key storage systems:
This separation of hot and structured storage optimizes for both speed and long-term consistency. Time-series databases like ClickHouse or TimescaleDB are ideal for Recent DB, while the Main DB often uses PostgreSQL for relational integrity.
Purpose: Low-latency querying for fresh data while maintaining long-term persistence for indexed datasets.
At regular intervals, a CRON job synchronizes the processed data into the Data Warehouse, which serves as the immutable “single source of truth.” This warehouse stores large historical datasets in object storage (e.g., Amazon S3) and supports high-performance analytics engines like ClickHouse or Redshift.
When deploying a new indexer, the system can bootstrap data directly from the warehouse rather than rescanning the blockchain — reducing sync time to under 10 minutes.
Purpose: Historical storage, reprocessing capability, and fast initialization for new indexers.
The EventBus (implemented via AWS EventBridge, Kafka, or Redpanda) serves as the backbone of the entire data pipeline. It decouples data ingestion from data processing, allowing hundreds of worker services to run in parallel.
Whenever a new block or event is detected, the ETL publishes it to the EventBus. Downstream processors subscribe to these topics to decode, enrich, and store the data — ensuring real-time scalability without blocking the main ingestion flow.
Purpose: Distribute workload asynchronously and enable parallel, event-driven data processing across the system.
The Processor, often implemented as AWS Lambda or lightweight microservices, subscribes to the EventBus.
It decodes raw blockchain events (e.g., Move VM events on Aptos), enriches them with external data (like token prices or metadata), and performs computations such as aggregations, counters, or analytics before writing results to the Indexer DB.
Each processor function is designed to be idempotent, ensuring reliability even with retries or duplicate events. Because these functions scale automatically with incoming events, they are cost-efficient and can handle massive throughput without manual scaling.
Purpose: Transform raw events into structured, analytics-ready data for querying and dashboards.
Each user or project in the system is provisioned with its own dedicated Indexer DB, which stores the processed data relevant to that specific tenant. This design ensures complete data and performance isolation: one user’s heavy workload never impacts another’s.
The Indexer DBs are often powered by NeonDB (serverless PostgreSQL) or similar technologies, providing automatic scaling, branching, and cost optimization.
Purpose: Tenant-level data isolation and independent scalability for each indexer instance.
Once data is written into the Indexer DB, it’s exposed through a GraphQL API (using Hasura) or a RESTful endpoint.
Hasura automatically generates the API schema from the database structure, allowing developers to query data, subscribe to updates, and integrate results into dashboards or applications instantly.
This layer also includes authentication, rate limiting, and real-time subscriptions over WebSockets, ensuring both speed and security for developers.
Purpose: Provide a unified, developer-friendly API layer for querying on-chain data.
Before data even reaches the indexer, smart contracts are analyzed by the AI Schema Generator.
This component uses LLMs (via LangChain / OpenRouter) to inspect contract ABIs and automatically generate optimized database schemas.
The result is a low-code experience where developers can create a new indexer in minutes without manually mapping every field.
This not only accelerates onboarding but also ensures schema consistency across projects.
Purpose: Automate schema generation and speed up indexer deployment.
A Lambda API acts as the control layer, coordinating system health, indexer states, and lifecycle management. It checks whether a contract is actively being indexed, determines if an indexer is suspended or idle, and manages throttling or auto-scaling triggers.
This orchestration layer ensures that the system remains responsive, efficient, and stable — even under fluctuating workloads.
Purpose: Monitor, control, and optimize the runtime behavior of all indexers in the ecosystem.
Unlike monolithic indexers that process everything in a single shared system, this distributed architecture decomposes workloads into isolated, on-demand environments.
Each tenant’s indexer scales independently, preventing noisy neighbors and reducing operational overhead.
With data already structured in the warehouse and schemas auto-generated by AI, new indexers can deploy and sync in under ten minutes, dramatically accelerating time-to-production.
By combining event-driven processing, serverless execution, and per-tenant databases, the architecture achieves true horizontal scalability — capable of handling millions of concurrent queries per second while maintaining predictable performance and low cost.
_Authors: Anderson Dao, Jay _